0.引言
前几期我们讲解了如何安装redis,redis的主从、哨兵模式,但还是没有触及到redis的真正核心竞争力——集群模式。
前一阵出品的Dragonfly经评测性能秒杀redis,但实际上仅仅只是单核服务器下的性能对比,而在redis主推的多核集群模式下,Dragonfly仍然被甩一大截。
所以我们今天来看看如何搭建redis集群
1. 原理
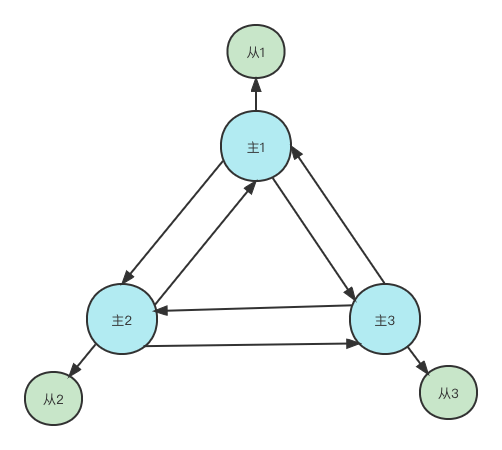
因为redis的容错机制是投票半数以上才认为某个节点挂了,2个节点的一半是1,而超过半数最少是2,因此即使是2节点的集群,也最少需要2个节点投票才能踢出某个宕机的节点,保证可用性。
总共就2个节点,1个挂了还剩1个,自然无法凑出2个节点投票,所以形成redis集群至少需要3个节点。
同时为了保证高可用性,一个节点应该有一个备用节点,即主从架构,所以最少需要6个节点才能搭建一个高可用的redis集群。
更多原理及教程可以参考redis官方文档:
1.1 hash槽
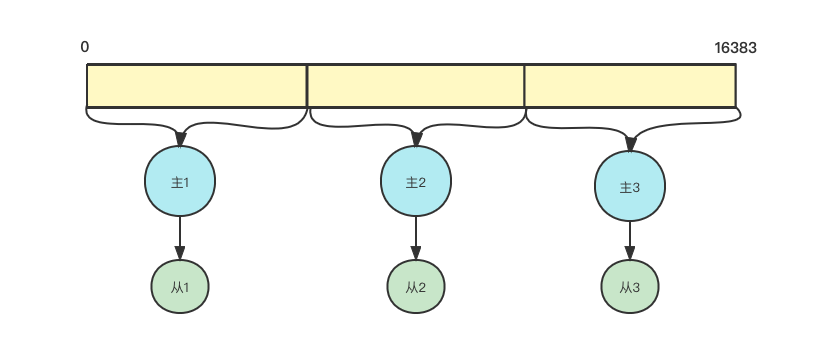
引入集群的目的是为了多个节点分摊数据压力,也就是我们常说的分而治之。
而一旦分治后,数据的读取就成了问题。打个比方,我存入一个key1的key,这个key被分配到了节点1,再次读取时如果定位到这个key所在的服务器呢?
不可以让用户手动切换吧。
于是乎就产生了hash槽的概念。
一共有16384(2^14)个哈希槽,集群的每个主节点负责一部分hash槽,每个key通过CRC16校验后对16384取余来看这个key应该放在哪个hash槽,通过槽位定位到具体的服务器节点
后续就自动跳转到槽位对应的服务器上进行读写操作了
1.2 重定向
但我们要知道,redis集群前面可没有一个负载均衡层来帮我们自动分发到对应的节点上。那么当客户端发出一个请求后,redis是如何知道这个请求的key应该分配到哪个节点呢?
这就需要每个主节点除了要知道自己的hash槽,也要知道集群中其他主节点的hash槽。
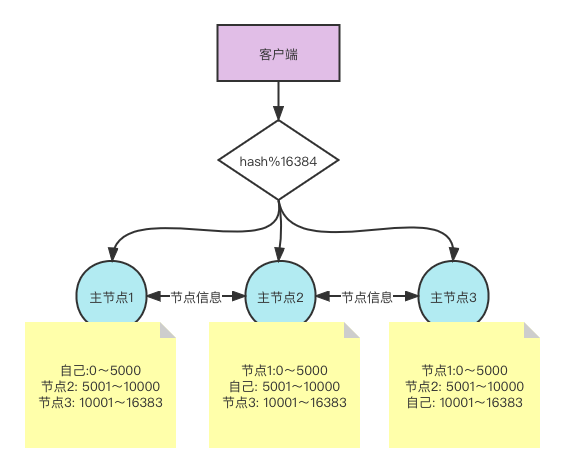
客户端可以直接向集群中任意节点发起查询请求,节点接收到该查询后,会看这个key的hash取余在不在自己的槽位,如果在就处理返回数据,如果不在则是返回一个MOVED 错误。会显示能够处理这个key的目标节点
GET x
-MOVED 3999 127.0.0.1:6381
如果我们直接使用redis-cli客户端连接集群是不会帮我们自动重定向到目标节点的,而是抛出一个错误。
如果想要自动重定向,可以使用redis-cli -c来连接集群,即多添加一个-c参数
1.3 集群的限制
- 1、聚合操作难实现
因为数据都被分发到了不同的节点上,要想实现聚合操作的话,就要要求把目标数据先查询出来放到一个地方,然后再基于此实现聚合操作。
但这样的逻辑会导致查询速度变慢,因为要先做数据的汇总查询,并且存放到一个集中的地方,还要占据资源,redis的核心思想是行计算向数据靠拢,也就是优先考虑查询速度。因此集群中如果数据存放在不同的节点,是不支持某些批量操作的,比如mset,mget
而作为替代方案,redis提供了一个hash tag来给不同的key打标签,相同标签的会被分配到同一个节点上。格式:set {tag}key value,比如
set {phone}apple 10000
set {phone}huawei 8000
set {phone}xiaomi 4000
- 2、多个key分布在不同的节点上,无法使用事务
- 3、集群模式下只支持一个数据空间,即db0
2. 从零搭建
2.1 搭建集群
1、 安装6个redis节点,具体可以参考上述安装博文;
2、 搭建集群的最小配置如下:;
# 端口
port 6379
# 开启集群
cluster-enabled yes
# 保存节点配置文件的路径,无需配置,默认值nodes-6379.conf
cluster-config-file nodes-6379.conf
# 集群节点丽连接超时时间
cluster-node-timeout 15000
# 开启AOF持久化功能
appendonly yes
3、 我们增加一些配置;
# 后台运行
daemonize yes
# 设置日志目录
logfile /var/local/redis/logs/6379.log
4、 每个节点上开启16379集群总线端口;
# 开启端口
firewall-cmd --add-port=16379/tcp --permanent
# 开启后重新加载
firewall-cmd --reload
5、 在任一节点创建集群(无需每个节点执行),让各个节点连接成一个集群,并且设置每个主节点的从节点个数为1;
redis-cli --cluster create 192.168.244.27:6379 192.168.244.28:6379 192.168.244.29:6379 192.168.244.30:6379 192.168.244.31:6379 192.168.244.32:6379 --cluster-replicas 1
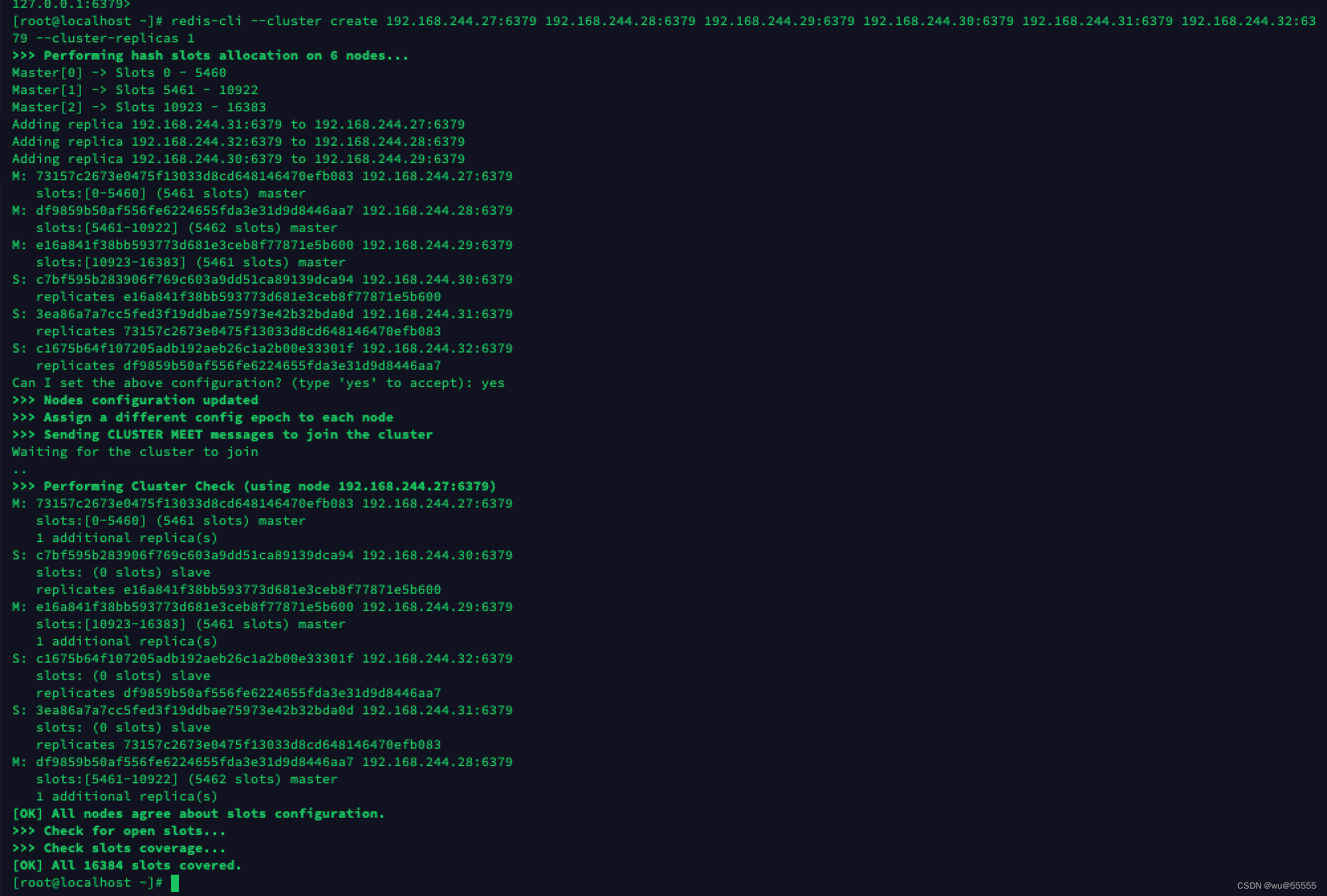
6、 查询集群节点信息;
redis-cli -p 6379 cluster nodes

可以看到集群节点分配为三主三从
2.2 测试
1、 连接一台主节点;
redis-cli -h 192.168.244.27 -p 6379
2、 添加xxx到27服务器成功,说明xxx的hash正好处于27服务器的hash槽位;
再添加oooo到27服务器,可以看到报错,并且提示该key的hash处于29服务器的hash槽位
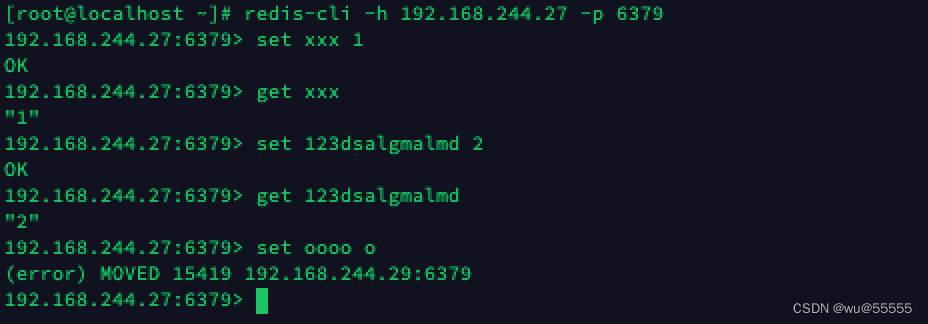
3、 登陆到29服务器,再次添加oooo,可以看到执行成功了;

4、 我们再模拟将其中一个主节点宕机;
ps -ef | grep redis
kill -9 1790
5、 查看节点状态;
redis-cli -p 6379 cluster nodes

结果发现29服务器已经标注为fail了,且30服务器(原从节点)转换为主节点了。主从自动切换了。
至此我们的集群搭建就完成了。
2.3. 常见报错
2.3.1. Not all 16384 slots are covered by nodes
这是因为主节点移除了,但是没有移除分配在上面的哈希槽,从而使得总数没有打到16384。可以检查下是哪个节点上的槽位分配有问题,然后重新分配一下。
- redis早期版本解决方式:
1、 先安装ruby环境;
yum install ruby
2、 检查节点;
src/redis-trib.rb check 192.168.244.27:6379
3、 修复节点;
src/redis-trib.rb fix 192.168.244.27:6379
4、 重新分配slot;
src/redis-trib.rb reshard 192.168.244.27:6379
- 新版本解决方式:
redis6.0中已经将redis-trib.rb指令集合到redis-cli中了,直接使用redis-cli即可:
1、 检查节点分配状态,这里输入任意节点IP即可,会自动检查所有节点;
redis-cli --cluster check 192.168.244.27:6379
2、 修复slot;
redis-cli --cluster fix 192.168.244.27:6379
确认输入yes
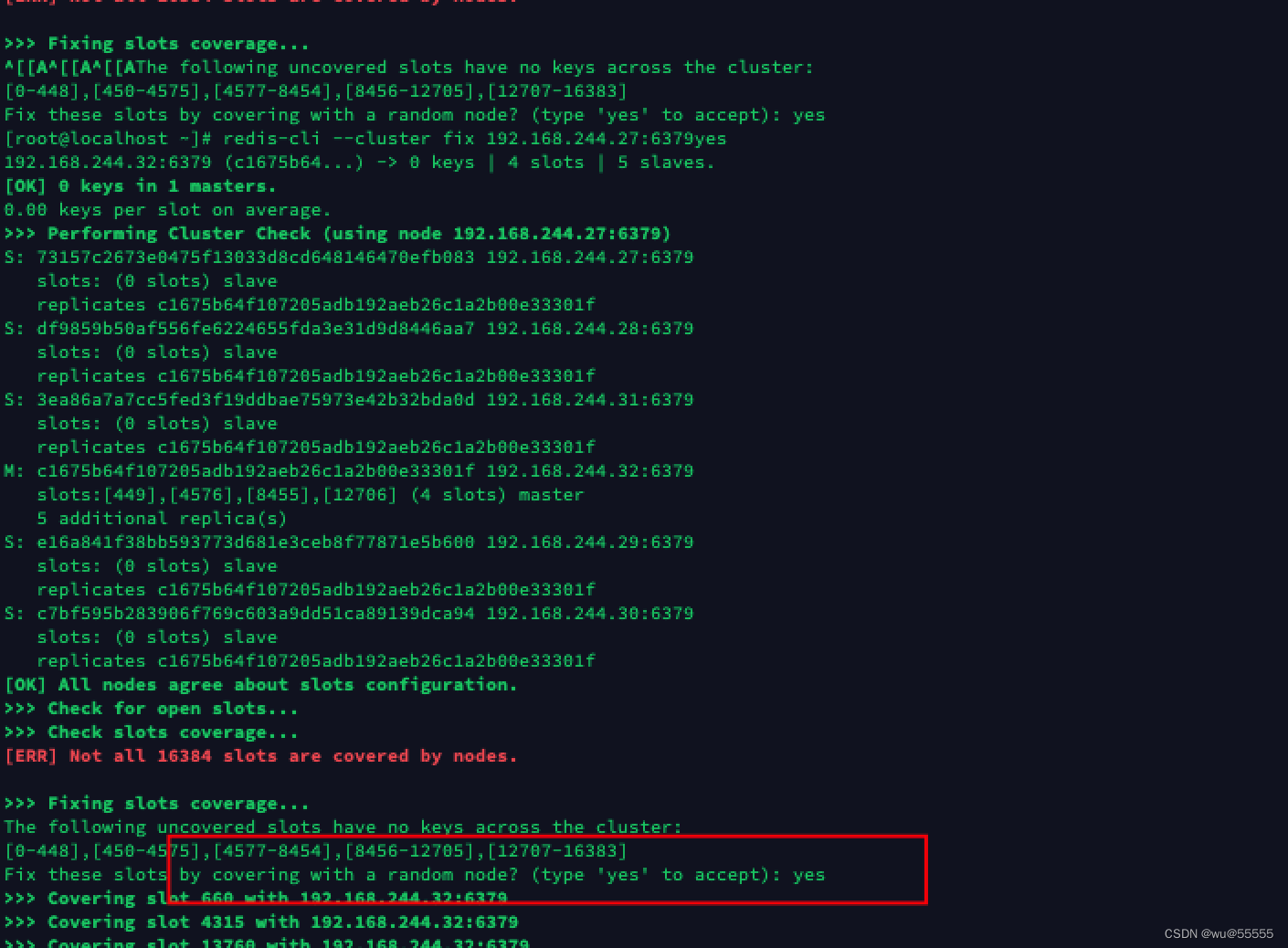
3、 手动重新分配哈希槽;
redis-cli --cluster reshard 192.168.244.27:6379
2.3.2.Node 192.168.244.27:6379 is not empty
详细报错:
[ERR] Node 192.168.244.27:6379 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
解决:
1、 登陆redis;
redis-cli
2、 清空对应节点的数据;
flushall
cluster reset